|
Visual Attention |
||
|
|
My main area of expertise is visual selective
attention, and especially, how the visual system selects information from cluttered
visual scenes. Specifically, I am trying to gain a deeper understanding
about how much control we have over attention and eye movements, what the
limitations are, and the factors and mechanisms underlying visual selection. My work has been greatly influenced by Anne Treisman's
Feature Integration Theory, Jeremy Wolfe's Guided Search model, various
saliency-based models of visual search, and the Contingent Capture Account
of Chip Folk and Roger Remington. My own work shows that we indeed have a
large amount of control over visual selective attention, as we can tune
attention to sought-after objects which then quickly attract the gaze when
they are present. There are however also bottom-up limitations to this
goal-driven selection process that can completely frustrate our attempts to
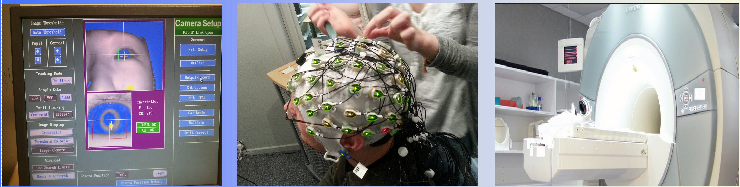
find an object. For my work, I'm using a variety of different methods,
including eye-tracking, EEG and fMRI - shown in the pictures below (from
left to right). The Relational Account (Becker, 2010) One of my central contributions to date is the demonstration
that attentional selection is not typically tuned to absolute feature values
(e.g., specific colours, sizes, or shapes), as assumed by dominant models of
visual search. Instead, attention is preferentially tuned to relational
properties of stimuli - such as “redder,” “brighter,” or “larger” - defined
relative to the surrounding context. This framework, which emphasises
context-dependent attentional tuning, has become known as the
Relational Account. According to the Relational Account, the visual system
automatically computes how a target differs from surrounding items within a
given context. For example, for an orange target, the system determines
whether it is relatively “redder” or “yellower” than the background.
Attention is then directed toward the item that best matches this relational
specification - namely, the reddest or yellowest element in the display. How do we select the goal keeper in these two images?
When searching for a goalkeeper wearing an orange shirt, feature-specific
accounts predict that attention is tuned to the colour orange across both
contexts. In contrast, the Relational
Account predicts context-dependent tuning: when the goalkeeper appears
within a yellow team, attention is biased toward relatively “redder” items,
whereas within a red team, attention is biased toward relatively “yellower”
items.
Emotions and Attention A second big topic of my research concerns how emotions can
guide attention. Together with Gernot Horstmann, Ottmar Lipp, Alan Pegna and
others, I investigated how emotional facial expressions and surprising
stimuli can attract attention and our gaze. While emotions are very possibly the
most important driving factor in our decisions and actions, our research so
far suggests that attention and eye movements are more strongly influenced
by perceptual factors than emotional factors. For example, in 'normal' angry
and happy schematic faces (left images), the angry face is found faster than
the happy face. However, by changing the contour of the face, the results
pattern reverses, so that happy faces can be found faster than angry faces. Changing the contour does not change the emotional
expressions. Hence, our explanation is that the 'normal' angry faces can be
found faster because the happy faces have a better Gestalt and can therefore
be grouped and rejected more easily when they are the distractors. Hence, faster
search for angry faces is not driven by the emotional contents of the faces, but
by their perceptual properties. In these experiments, effects previously attributed to the
processing of the target emotion were found to arise mainly from the
perceptual properties of the distractor set ('grouping'). One approach to
assessing the extent to which distractors can be perceptually grouped is to
manipulate the visible area during visual search using a moving-window
paradigm. By restricting visibility to either a small or larger region
centred on fixation, this method allows estimation of the number of
distractors that are effectively processed and grouped under different
conditions (e.g., angry vs. happy faces). The video below provides an
illustration of this technique. (The red dot indicating eye position was not
visible to participants during the experiment.) The fact that attention and eye movements are strongly
influenced by perceptual factors does not mean that emotional expressions or
our own emotional states will exert no effects on attention.
Rather, such effects are likely to be more subtle and may require sensitive
and carefully designed paradigms to detect. In subsequent work, we have held
the stimulus properties constant while experimentally manipulating
participants’ mood. These studies showed significant congruency effects
between the participants' mood and the valence of emotional stimuli on both
eye movements and search performance, showing that emotions can in fact
modulate attention.
Sensory Substitution In sensory substitution, we replace information usually conveyed by one sense (e.g., vision) by another sense (e.g., hearing or touch). Sensory substition research thus has the potential to help people who lack a sensory modality (e.g., vision-impaired or blind people). It also allows investigating some fundamental questions about how the brain interprets visual information, first, because Interpreting visual information that is conveyed through another sense requires learning. Second, the brains of people who lack a sensory modality are different, because their brains have adapted and use other sources of information to gain the same knowledge that is usually provided by vision. The visual cortex in blind people is very active, even in people who have never used their eyes. However, it is still a mystery what the visual cortex is doing, and even, whether it is indeed still a 'visual cortex', or whether it is now used to process exclusively tactile or auditory information (Neuroplasticity). Sensory substition research allows us to unravel this mystery, thus providing new insights into vision and neuroplasticity.
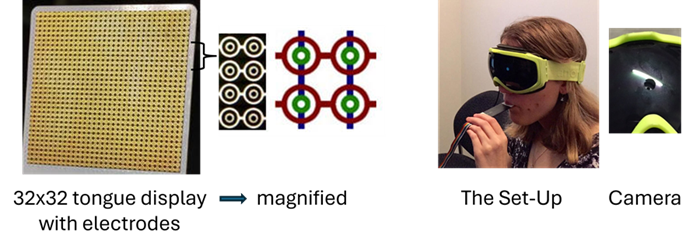
Our sensory substitution device: Several years ago, we developed an electro-tactile sensory
substitution device (SSD) that translates visual input from a video camera
into patterned stimulation on a 32×32 tongue-based tactile display. The
tongue display hardware was developed by engineers Ernst Ditges and Nick
Sibbald, while Dustin Venini (then a postgraduate student) refined the
encoding algorithms and programmed the experimental paradigms. In our SSD, we embedded a video camera within blacked-out
ski goggles, and converted visual inputs into a simplified black-and-white
representation. As a result, visual information - such as the movement and
shape of an object - is conveyed through corresponding spatiotemporal
patterns on the tongue, allowing users to perceive objects and environmental
changes despite the absence of visual input.
In contrast to other electro-tactile sensory substitution
devices (SSDs) at the time, our system implemented a display logic analogous
to that used in LCD technology. An electrical potential was applied to
columns corresponding to active (e.g., high-contrast) pixels, while the
image was rendered by sequentially delivering brief electrical pulses across
the 32 rows. Due to the rapid cycling of stimulation across rows, users
still perceive a coherent, continuous image rather than discrete activation
of individual sections of the tactile display. Using this approach, our sensory substitution device (SSD)
achieved substantially higher spatial and temporal resolution than
comparable systems (e.g., BrainPort, Wicab Inc.). Whereas existing devices
were typically limited to temporal resolutions of approximately 5 Hz
(insufficient for representing fast-moving objects), our system operated at
the native frame rate of the video input (30 Hz), enabling the perception of
dynamic stimuli. In addition, our device provided enhanced
spatial resolution, employing a 32×32 electrode array compared to the
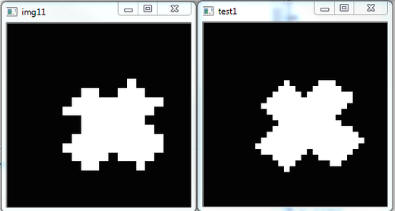
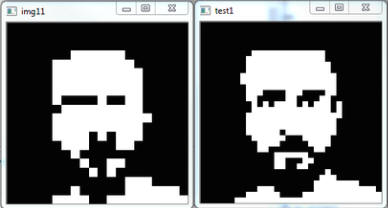
approximately 20×20 matrices used in other SSDs. As illustrated in the Figure below, this
increased spatial resolution is critical for supporting object recognition
and the perception of fine-grained spatial detail. The images below show a
cross and a face (D. Venini) at 20×20 resolution (middle image) and 32×32
resolution (right image). White pixels indicate electrodes that are
activated and perceived on the tongue. We evaluated the performance of the SSD in object
localisation and recognition tasks, including conditions involving dynamic
stimuli, across a range of spatial and temporal resolutions. The results
demonstrated that previously reported limitations in perceiving fast-moving
objects primarily reflect the restricted temporal resolution of earlier
devices, rather than inherent constraints of the human perceptual system
(see Venini's thesis for
details). We are happy to share the full technical details of the SSD
and all software with interested parties to support independent replication
and further development. Please contact Stefanie Becker (s.becker@psy.uq.edu.au)
to request access to the design files. The printed circuit boards (PCBs)
were designed using Eagle 6.5 and manufactured by PCBcart based on Gerber
files. The videos below illustrate performance using the SSD in the
absence of visual input, showing a naïve participant completing an object
localisation task and a more experienced participant stacking cups using
only tactile inputs from our SSD. Touch Screen Experiment In this experiment, a 6 cm white target
was presented at one of 32 possible locations on a touchscreen. Participants
were required to localise the target and indicate its position by touching
the corresponding location with their index finger, using information
conveyed via the tongue display while wearing blacked-out ski goggles. The figure below illustrates the tactile
representation of both the target and the participant’s hand, and the video
on the right shows the progression from initial localisation to accurate
target contact, based on performance by participants with very limited prior
experience with the task and the SSD.
Stacking Cups When participants finish an experiment early, we often
informally test some new tasks that are in the planning stage, to receive
participant's feedback about how difficult the task is, where exactly the
difficulties are and how we could improve it. On this note, I would like to
highlight that our participants so far have been absolutely fantastic in
providing us with feedback. A big thank you to all our participants, and
especially those from the vision-impaired population, for helping us with
this project. We really could not have wished for better participants. In the video below, you can watch one of our blind
participants stacking plastic cups with the tactile display. Enjoy the video!
|